■概要
以下に今回実装する処理概要を記載する。
- ログファイルのパスを定義
- 関数
read_log_file()を定義
- ログファイルをUTF-8で開く
- ファイルの全行を1行ずつ処理
- 各行を
'|'区切りで分割
- ログ種別を判定(「02」の場合のみ以下を実施)
- ログのデータ部を取得
- データ部の前置詞
"data: "を削除 key=value形式の文字列を辞書に変換
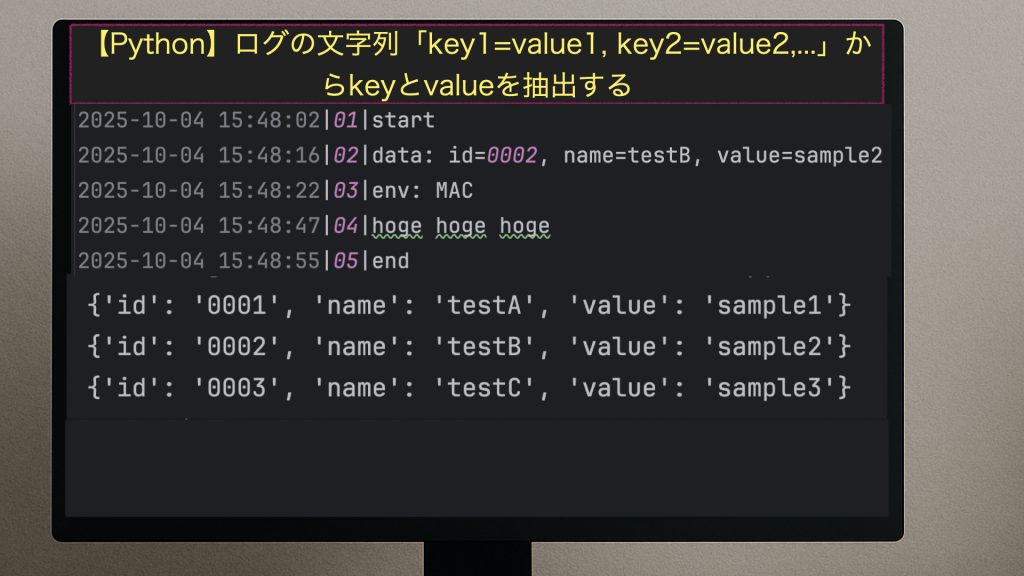
なお読み取るログファイルは以下とする。
・./logs/sample.log
2025-10-04 15:47:02|01|start
2025-10-04 15:47:16|02|data: id=0001, name=testA, value=sample1
2025-10-04 15:47:22|03|env: MAC
2025-10-04 15:47:47|04|hoge hoge hoge
2025-10-04 15:47:55|05|end
2025-10-04 15:48:02|01|start
2025-10-04 15:48:16|02|data: id=0002, name=testB, value=sample2
2025-10-04 15:48:22|03|env: MAC
2025-10-04 15:48:47|04|hoge hoge hoge
2025-10-04 15:48:55|05|end
2025-10-04 15:49:02|01|start
2025-10-04 15:49:16|02|data: id=0003, name=testC, value=sample3
2025-10-04 15:49:22|03|env: MAC
2025-10-04 15:49:47|04|hoge hoge hoge
2025-10-04 15:49:55|05|end
■フローチャート
以下に今回実装する処理のフローチャートを示す。
■サンプルコード
以下に今回実装するサンプルコードを示す。
LOG_FILE_PATH = './logs/sample.log'
def read_log_file():
# ログファイルを開く
with open(LOG_FILE_PATH, 'r', encoding='utf-8') as f:
# ログファイル内の行数分繰り返し
for line in f:
# ログデータを'|'で分割
log_list = line.strip().split('|')
# ログ種別の02(データ部)の場合
if log_list[1] == '02':
# ログのデータ部を取得
log_data = log_list[2]
# 先頭の "data: " を除去
data_line = log_data.replace("data:", "", 1).strip()
# key1=value1, key2=value2,...を辞書型に格納
data = {k.strip(): v.strip() for k, v in
(item.split('=') for item in data_line.split(','))}
print(data)
if __name__ == '__main__':
read_log_file()
■実行結果
{'id': '0001', 'name': 'testA', 'value': 'sample1'}
{'id': '0002', 'name': 'testB', 'value': 'sample2'}
{'id': '0003', 'name': 'testC', 'value': 'sample3'}

コメント