■確率密度を図示
以下のデータを使用して、ヒストグラムの作成および確率密度を図示する。
SampleData.csv
size
1
2
2
3
3
3
4
4
4
4
5
5
5
5
5
6
6
6
6
7
7
7
8
8
9■サンプルコード
【ライブラリのインポート】
import numpy as np
import pandas as pd
import scipy as sp
from scipy import stats
from matplotlib import pyplot as plt
import seaborn as sns【サンプルデータの取得および表示】
# サンプルデータを取得(read_csvファイル読み込み)
sample_data = pd.read_csv("SampleData.csv")
# サンプルデータを表示
print(sample_data)・実行結果
size
0 1
1 2
2 2
3 3
4 3
5 3
6 4
7 4
8 4
9 4
10 5
11 5
12 5
13 5
14 5
15 6
16 6
17 6
18 6
19 7
20 7
21 7
22 8
23 8
24 9【サンプルデータの平均・標準偏差の取得および表示】
# 平均を算出(numpyの関数を使用)
mean_value = np.mean(sample_data)
# 標準偏差を算出(numpyの関数を使用)
sd_value = np.std(sample_data)
# 平均と標準偏差を表示
print('平均:' + str(mean_value))
print('標準偏差:' + str(sd_value))・実行結果
平均:size 5.0
標準偏差:size 2.0【サンプルデータのヒストグラムを表示】
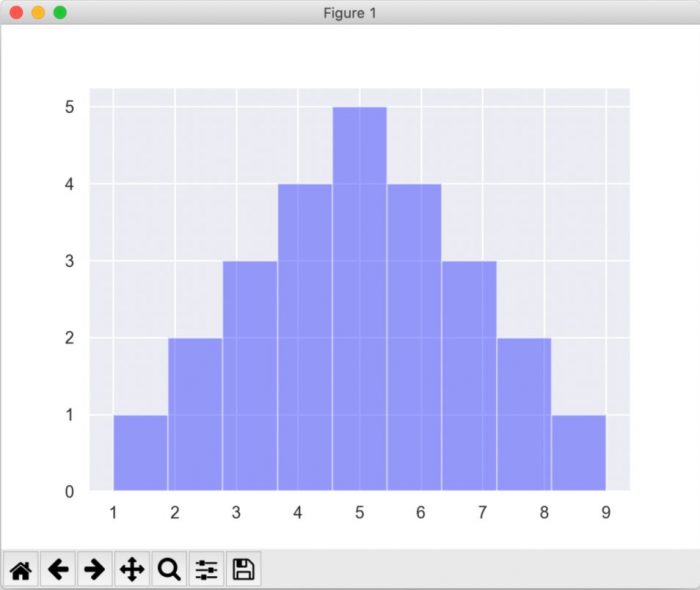
# グラフのデザイン変更
sns.set()
# ヒストグラムをセット
sns.distplot(sample_data, bins = 9, kde = False, color = 'blue')
# グラフを表示
plt.show()・実行結果
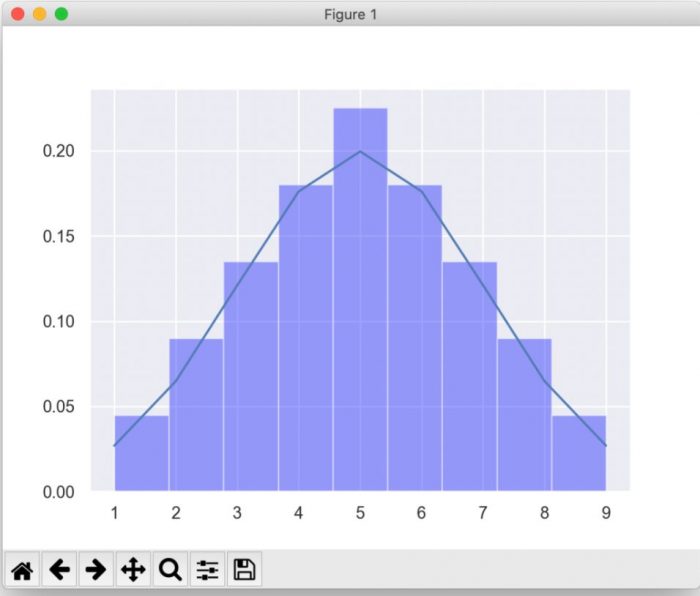
【サンプルデータの確率密度を表示】
ヒストグラムの累計値を1にする場合は、norm_hist = Trueを使用する。
確率密度の計算は、stats.norm.pdf関数を使用する。
なお、stats.norm.pdf関数の引数は以下の通り。
x :サンプルデータ
loc:平均の値
scale:標準偏差の値
# ヒストグラムの累計値を1にしてセット
sns.distplot(sample_data, bins = 9, norm_hist = True, kde = False, color = 'blue')
# 確率密度をセット
plt.plot(sample_data, stats.norm.pdf(x = sample_data, loc = mean_value, scale = sd_value))
# グラフを表示
plt.show()・実行結果


コメント