■2変量データ
以下の2つの品種に関してデータ解析を行う。
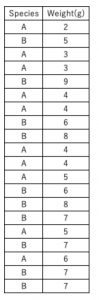
■csvファイルの作成
上記データについてcsvファイル(カンマ区切り)を作成する。
・ファイル名
SpeciesData.csv
・ファイルの中身
Species,Weight(g)
A,2
B,5
A,3
A,3
B,9
A,4
A,4
B,6
B,8
A,4
A,4
A,5
B,6
B,8
B,7
A,5
B,7
A,6
B,7
B,7■csvファイルの読み込み
pandasを使用してcsvファイルを読み込む
import pandas as pd
# csvファイル読み込み
SpeciesData = pd.read_csv("SpeciesData.csv")
# 読み込んだcsvファイルを表示
print(SpeciesData)・実行結果
Species Weight(g)
0 A 2
1 B 5
2 A 3
3 A 3
4 B 9
5 A 4
6 A 4
7 B 6
8 B 8
9 A 4
10 A 4
11 A 5
12 B 6
13 B 8
14 B 7
15 A 5
16 B 7
17 A 6
18 B 7
19 B 7■品種ごとの統計量を出力
import pandas as pd
# csvファイル読み込み
SpeciesData = pd.read_csv("SpeciesData.csv")
# 品種ごとの統計量を出力
print(SpeciesData.groupby("Species").describe())・実行結果
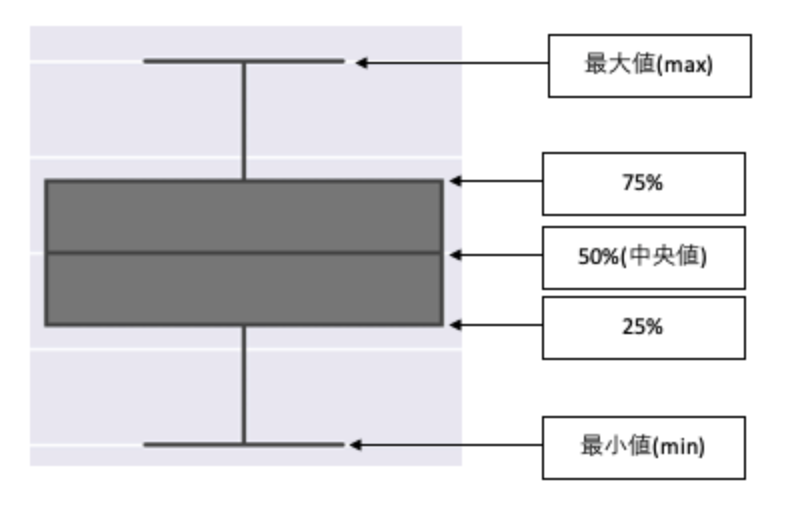
Weight(g)
count mean std min 25% 50% 75% max
Species
A 10.0 4.0 1.154701 2.0 3.25 4.0 4.75 6.0
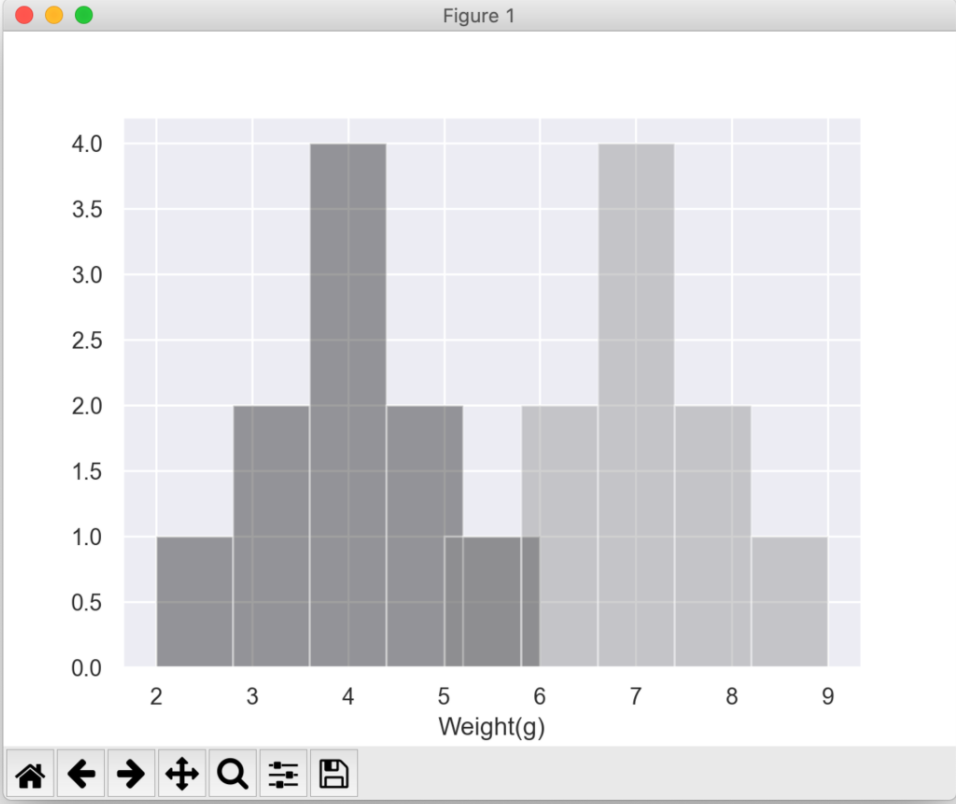
B 10.0 7.0 1.154701 5.0 6.25 7.0 7.75 9.0■ヒストグラムを表示
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
# csvファイル読み込み
SpeciesData = pd.read_csv("SpeciesData.csv")
# 品種ごとに変数に格納
SpeciesA = SpeciesData.query('Species == "A"')["Weight(g)"]
SpeciesB = SpeciesData.query('Species == "B"')["Weight(g)"]
# グラフのデザイン変更
sns.set()
# グラフの作成
sns.distplot(SpeciesA, bins = 5, color = 'black', kde = False)
sns.distplot(SpeciesB, bins = 5, color = 'gray', kde = False)
# グラフの表示
plt.show()・実行結果
コメント